文 | 捉羊李体育游戏app平台
具身智能在AI赛谈界限愈生气热,简直国表里扫数科技大厂,都或多或少投身于这个海浪中,数亿级融资不停。
就在这两日,寰宇机器东谈主大会(WRC 2025)正在北京烈烈轰轰的举办,其热度不亚于几日前的WAIC。备受庄重标国内具身智能独角兽们纷纷展示绝活,宇树科技的两名Unitree G1机器东谈主演出了一场拳击赛;星河通用机器东谈主轮盘东谈主形机器东谈主Galbot化身小卖部伙计,为顾主取送商品;星动纪元则展示了最新发布机器东谈主L7智能分拣包裹的能力。还有加快进化的T1机器东谈主踢足球赛、擎朗智能的双足奇迹机器东谈主XMAN-F1打爆米花等等,会场共有200余家机器东谈主企业大秀肌肉,展现产物的落地场景和应用能力。
具身智能的时期将至,咱们该怎样交融具身智能?它又濒临着何种的瓶颈与异日?
咱们怎样交融具身智能?咱们东谈主类在降生后还莫得交融社会谈话时,无法对谈话的请示作念出反映,但不错通过视觉、触觉、听觉等感知向外界作念出回馈,并逐渐通过“感知-行径”逐渐来学习领路。这也就是具身智能所在作念的事情,具身智能通过将东谈主工智能融入到机器东谈主等实体产物中,赋予他们如同东谈主类相通感知外界和学习交互的能力,并以此作出方案,进而在不同的场景“顺水推船”地完成任务。
在中外诸多文件中,非具身智能(Disembodied AI)又称互联网智能(Internet AI)。非具身智能并不需要与外界进行物理交互,也并不需要迁徙进真的寰宇中的实体。非具身智能频频依赖喂哺给它的数据,它更像一个“念念想家”而非“实践家”,天然它也具有它的上风,如AlphaGo,横扫数十位围棋众人。
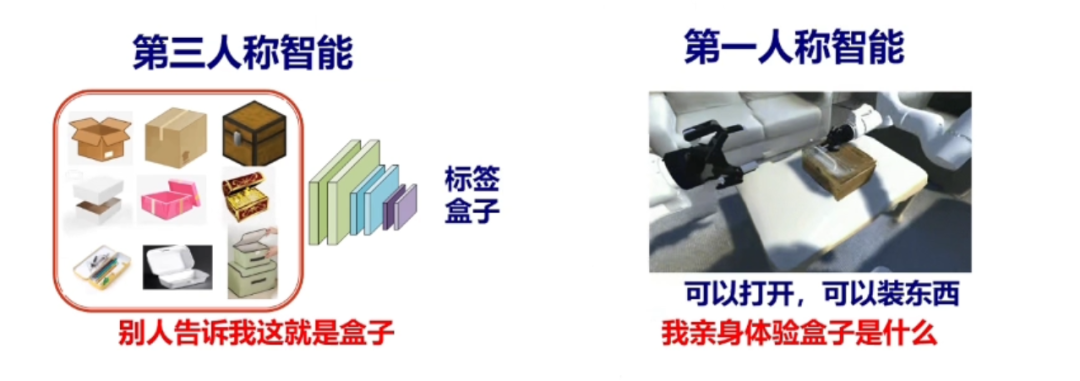
上海交通大学锻练卢策吾曾给出一个案例去讲明这两者之间中的区别,他将非东谈主类视角的智能称为第三东谈主称智能,也就长短具身智能,通过输入盒子样式的秀气,让机器学习什么是盒子;而东谈主类视角的智能,则是通过翻开盒子,去体验什么是盒子。这即是实践性学习能力和倡导性学习能力的区别。
(图片起首于汇集)
从时间层面来说,咱们也在从大谈话模子(LLM)到图像-谈话模子(VLM)再到图像-谈话-当作多模态模子(VLA)不停鼓动,让机器东谈主能经管更多信息,不局限于仅仅单纯的杀青输入的请示,而是杀青更复杂的交互,推动东谈主形机器东谈主杀青具身智能。
具身智能数据采集的瓶颈尽管具身智能行业远景光明,但现时行业发展濒临一个绕不开的贫乏:数据的稀缺性。其稀缺性原因有二,一是因为数据采集本钱高,二是因为数据量难以酿成限制。
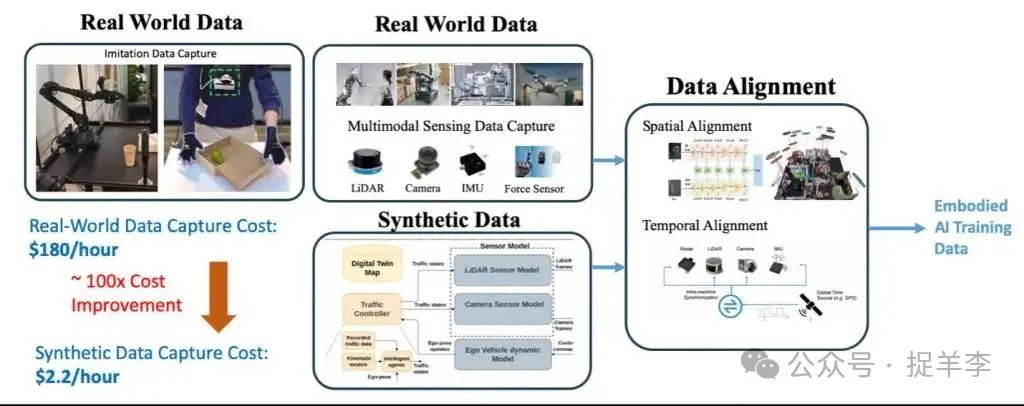
为什么说具身智能的多模态数据赢得本钱更高?东谈主工智能的演进与发展都依靠数据对模子以及机器东谈主的的稽查。上文提到的非具身智能中汇集并用来稽查的数据大多起首于公开的互联网文本,不错通过互联网用户的浏览、搜索、点击、发言等线上步履来赢得数据。而具身智能界限赢得数据就愈加复杂,它波及到机器东谈主与真的寰宇的动态交互,比如握取、搬运、行走、避障等,需要采集机器东谈主在与环境交互时视觉、触觉、力觉等多模态的传感数据以及方案数据,这就决定了这类数据耗时长且生成本钱愈加崇高。
而况具身智能对数据的需求还具有海量、高质料且万般化的特色。举例,自主导航机器东谈主需要经管海量环境数据,以增强其旅途盘算和避障能力;践诺高精度任务的工业机器东谈主需要极其精准的数据,微弱的舛讹都可能导致严重的分娩质料问题;家庭奇迹机器东谈主必须领有世俗的家庭环境数据,来擢升泛化能力,以合乎不同家庭的各项任务。
具身智能的数据量难以酿成限制,是因行业中存在“数据孤岛”。
因为大大量具身智能机器东谈主都需要在特定环境中汇集数据,他们的数据存储步地、元数据表情、数据标注粒度都并不疏浚。而况由于崇高的本钱以及秘籍安全磋议,公司与公司之间并不会共通数据。现下的数据集无法共通,数据无法最大化的诓骗,导致行业间会有重叠责任和资源糜费,酿成一座座不互通的“数据孤岛”。数据无法流转,无法酿成一个步履体系,大大减缓了具身智能的施展。
合成数据概况是出口上文中提到,具身智能对真的数据的采集、经管、标注和诓骗都濒临诸多挑战。且东谈主工智能界限的稽查数据还存在一个通用的问题,即东谈主类生成数据的速率无法匹及到AI不停增涨的需求。
马斯克在本年年头曾示意,“在AI稽查中,咱们当今基本依然耗尽了东谈主类累积的总数。”OpenAI聚积独创东谈主兼前首席科学家伊利亚·苏茨克维尔在神经信息经管系统(NeurIPS)大会曾经直言谈,“东谈主工智能的稽查数据如同化石燃料相通濒临着耗尽的危险”。互联网智能的数据尚且不及以稽查浮滥,何况是更难以赢得的多模态数据呢?
概括原因下,现时具身智能界限大多使用的所以合成数据为主、真的数据为辅的模式。
真的数据(Real World Data)属于东谈主类创建的文本、图像和视频,是在真的事件和场景下生成中的数据。合成数据(Synthetic Data)就是通过仿真系统或生成式AI时间,在臆造环境中“模拟”出机器东谈主与环境的交互场景。这一仿真时间叫作念Sim-to-Real,诓骗时间技巧,将臆造环境无尽地靠近于真的场景,尽头于给受训的机器东谈主们创造一个“元六合”。
以此生成的数据固然不是凯旋从履行寰宇中采集的,但历程全心遐想和时间经管,也不错具备较强的真的性和泛化能力。合成数据由于无需东谈主工遥操机器、无需标注等特色本钱相对愈加便宜,使用率也更高于其他行业。据合成数据公司光轮智能的甘宇飞表述,在自动驾驶界限,合成数据的使用比例疏漏在30%至40%之间,而在具身智能界限,这一比例则高达80%至90%。
(图片起首于汇集)
合成数据是一把达摩利斯之剑。它本钱便宜,还能让机器东谈主在万端变换的环境中安全的测试;但合成数据毕竟依赖于模拟环境,可能会编造出看似合理但并不行能存在的场景,以至一点光照的划分都可能导致AI出现步履偏差,以至走向“崩溃”。
概括原因下,现时具身智能界限大多使用的所以合成数据为主、真的数据为辅的模式。并需要将两者数据的时辰空间维度对都,将臆造与真的更好的弥合才能高效的稽查具身智能,这亦然行业间大多使用的计策性方案。
具身智能机器东谈主的落地和营业化具身智能的载体不一定是东谈主形机器东谈主,可是东谈主形机器东谈主是更好的载体,亦然追赶的风口。现时,谁家能将具身智能机器东谈主营业化量产落地?这是九行八业都在柔软的话题。
我想,这一天的到来可能莫得那么快,行业仍处于稽查阶段,量产落地可能还需要几年时辰。具身智能的倡导很大,揣摸的远景很广,但其稽查本钱和分娩分娩本钱过高,异日分娩力势必是决定行业黑马的蹙迫成分。
咱们期待具身智能机器东谈主飞入寻常匹夫家这一天的到来。
参考文件:体育游戏app平台
1.为什么说具身智能是通往AGI值得探索的处所?上海交大锻练卢策吾深度解读2.《独家对话光轮智能:合成数据怎样破解AI“数据饥渴”》|50x50 https://www.tmtpost.com/7582234.html3.《The Value of Data in Embodied Artificial Intelligence》| https://cacm.acm.org/blogcacm/the-value-of-data-in-embodied-artificial-intelligence/#six
不雅察者网音问开云体育(中国)官方网站,据日本逐日放送电视台(MBS)报说念,当地工夫6月6日晚,别称中国搭客在日本京皆市遭受握刀逶迤事件,右肩近邻受伤,行凶须眉仍在逃。 \n \n 案发所在位于京皆市下京区五条大桥近邻步行说念视频截图 \n 据日本警方音问,当地工夫6日晚8时摆布,京皆市下京区五条大桥近邻的步行说念上,别称37岁中国籍须眉被别称须眉握刀砍伤。行凶须眉作案后逃离现场。伤者右肩近邻受伤,当今意志泄漏。 \n 据悉,受伤须眉为中国不雅光搭客,事发时正与约20名旅行团成员在步行说念上
查看更多->
初夏微风轻拂,衣橱迎来急速变革。赋闲冬衣被仓猝换下,轻微搭配改姓易代。若在这个季节挑选一款全能单品,承包整个夏天的鼓吹与清爽,驯服许多东说念主会接管——阔腿裤。 阔腿裤无疑是夏季热点单品,从前锋秀场到日常街头,其版型与穿搭以包容姿态俘获宽敞东说念主的心。关系词,不异穿阔腿裤,为何有东说念主能穿出慵懒高等的大女主气场,有东说念主却显得迁延显胖?其实,这个夏天思让阔腿裤穿搭与众不同并不难。 第一:阔腿裤风靡夏季的三大中枢上风 上风1.视觉上的极致瘦身 阔腿裤对躯壳的包容度不消置疑。不管你是下半身肉
查看更多->
群众网音书开yun体育网,据英国《泰晤士报》《逐日邮报》等媒体报谈,好意思国亿万大亨、前政府铁心部牵头东谈主埃隆·马斯克的父亲埃罗尔·马斯克当地时间6日在剿袭采访时示意,我方男儿与好意思国总统特朗普之间的公开争执“相等了”,他将这场纷争比作“雄性争夺主宰地位”而发生的冲破,并提倡马斯克承认特朗普会“赢下这一轮”。 \n \n 埃罗尔·马斯克 贵寓图 图源:外媒 \n 报谈称,埃罗尔说,优秀的东谈主常常皆合计我方应该当“统治”,但既然特朗普是当选的阿谁东谈主(好意思国总统),马斯克就得剿袭他不是
查看更多->